Presentation of Search Results
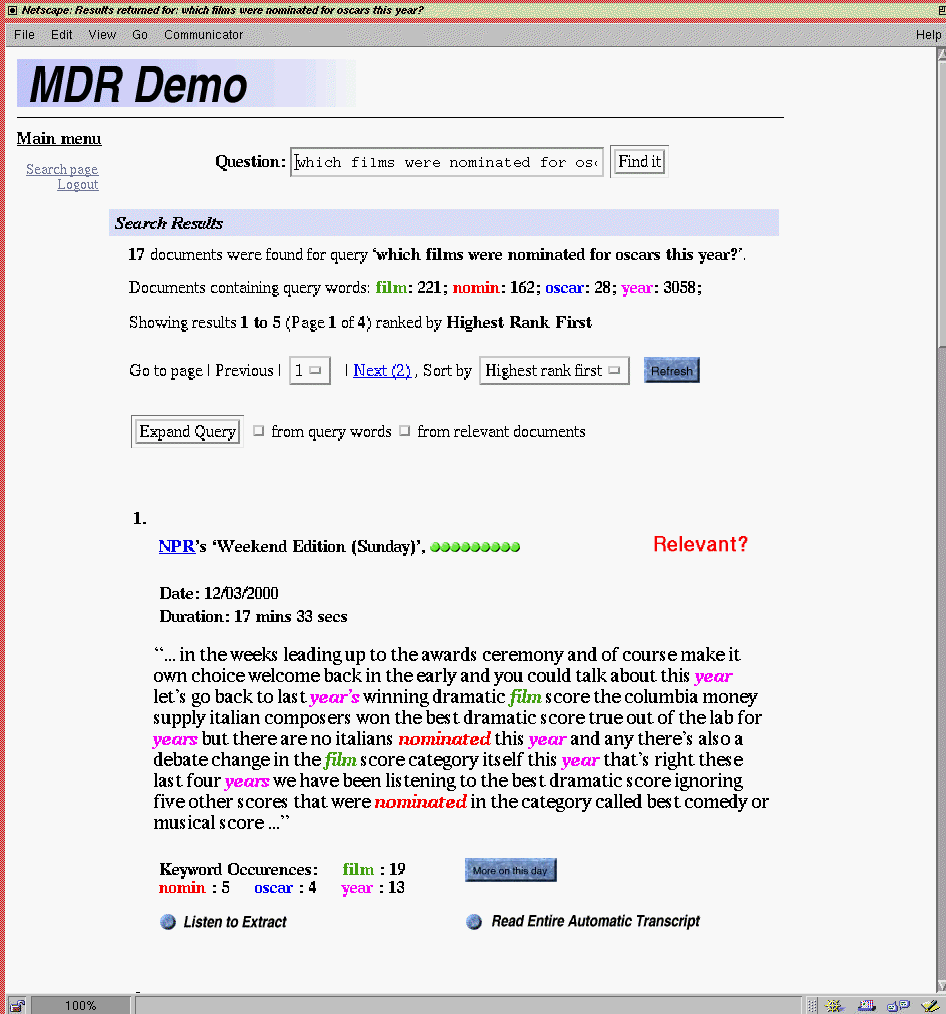
The results of a search are presented on one or several pages if necessary. An example of a results page can be seen below.The top of the results page contains the query for which the results are returned. In this example the query was "Which films were nominated for Oscars this year?". The results page shows the user that the retriever found 17 documents that it believes are relevant to the query. It also shows how many documents contain each of the query words. For instance, the word film occurs in 221 documents in the data base. This number indicates the usefulness of a query word. Query words that appear in most of the documents of the data base might not be specific enough to help the retriever find the relevant documents. On the other hand query words that appear only in a few documents might give a strong indication as to what the relevant documents are.
One can also see from this list that the information retriever removes the endings of the query words. Here the word "nominated" has been stemmed to "nomin". This technique ensures that documents which contain related words which share the same stem will be found, even if they don't contain the original word. For example in this case, the retriever will also find documents containing the words "nominate", "nomination", "nominating", and "nominee" etc. You will notice these stemmed words elsewhere in this introduction and the demo snapshot. Usually, it shouldn't be too difficult to find out which words belong to a given word stem.
The following line allows the user to select one of possibly several pages of search results and order them according to a different sorting criterion. The sorting criteria supported in the MDR demo are "most relevant document first", "least relevant document first", "newest document first", "oldest document first".
The next line allows the user to expand the query by selecting one or two different methods. These methods will be discussed in section Query Expansion.
Below this line one can see the first extract of a document that was found by the retriever. The extract is the section of roughly one hundred words in the transcription that was produced by the automatic speech recogniser that has the highest density of query words in it. As in the rest of the page the query words are highlighted in different colours in these extracts. The different colours don't have any meaning by themselves. They are just there to improve the readability of the automatic transcription.
For each extract the results page also shows when the corresponding audio was broadcast and by which station. In the example results page the document that is represented by the extract was broadcast during National Public Radio's Weekend Edition on March 12, 2000. The duration of the whole document is 17 minutes and 33 seconds. Right next to the information about the origin of the broadcast is a line of green dots. These indicate the relevance of the document relative to the most relevant document in the current search. If the documents are sorted according to the highest relevance first criterion which is the case in this example the first document always has only green dots. Only for documents later in the sequence some of the dots are grey. The red "Relevant?" button at the end of the line is a toggle button that allows to mark the document as relevant. Clicking on this button changes it to a green "Relevant!" button. This button is used in connection with one of two query expansion methods that will be discussed in section Relevance Feedback.
Below each extract the results page shows the number of times each of the query words occurred in the document. For instance, "Oscar" occurred 4 times in the document that is represented by extract one. Next to this is a button that allows the user to narrow down the list of returned documents to the ones that were broadcast on the same day as the document currently under consideration. In this example one would retrieve only documents that were broadcast on March 12, 2000. The following line contains a button that plays the audio that corresponds to the extract. The audio files are RealAudio encoded. In order for this button to work one therefore has to have the RealPlayer installed and a properly set up browser. The "Read Entire Automatic Transcript" button opens the automatic transcription of the whole document in a new window.
An example page containing a complete transcription can be found below. The user can play selected parts of the audio by highlighting a section of text on this page. One can see from this example page that the transcription is not perfect. But the general level of recognition accuracy remains high enough to effectively retrieve the broadcast documents of interest.