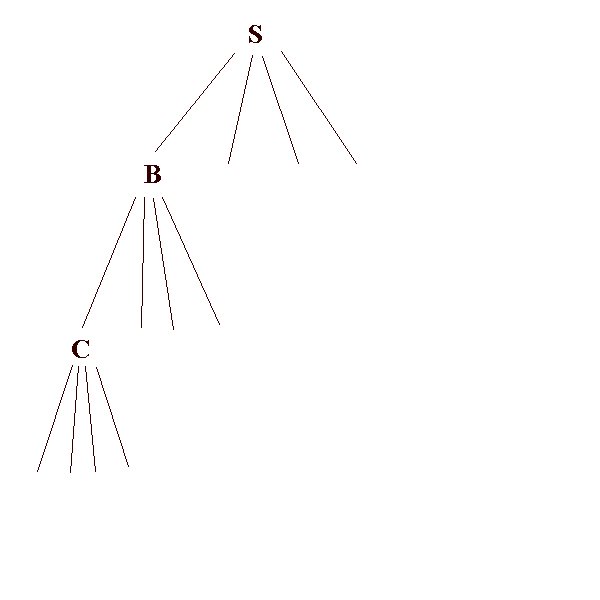
The depth-first algorithm is:
The first two methods are UNINFORMED.
The depth-first algorithm is:
1. Form a one element queue Q consisting of the root node.
2. Until the Q is empty or the goal has been reached, determine if the first element in the Q is the goal.2a. If it is, do nothing.3. If the goal is reached, success; else failure.
2b. If is isn't, remove the first elment from the Q and add the first element's children, if any, to the FRONT of the Q.
Depth-first search is simple, but is very unsatisfactory if the tree is unbalanced, with some leaves being at the end of much longer branches than others. It lacks discrimination.
Completeness: Yes
Time efficiency: No
Space efficiency: Yes
Optimality: No
In this technique you search for the goal node among all nodes of a particular
generation before expanding further. This way you always catch the node nearest
the root in generations. This is of value if the tree is unbalanced, but is
wasteful if all the goal nodes are at similar levels. Why? Consider a tree with
branching factor b. At level k there are bk nodes, which can be very
large - we must be wary of anything involving exponential size and time.
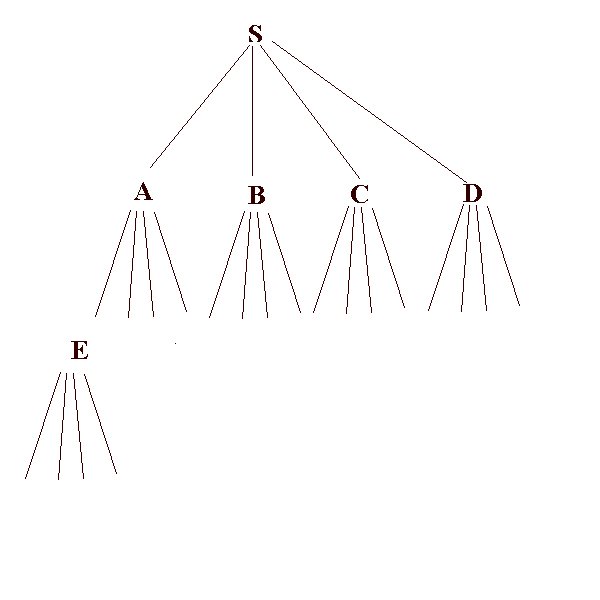
The breadth-first algorithm is:
1. Form a one element queue Q consisting of the root node.
2. Until the Q is empty or the goal has been reached, determine if the first element in the Q is the goal.2a. If it is, do nothing.
2b. If is isn't, remove the first element from the Q, and add the first element's children, if any, to the BACK of the Q.3. If the goal is reached, success; else failure.
Completeness: Yes
Time efficiency: No
Space efficiency: No
Optimality: No