| enginuity |
|
A word in your Gigabyte
Imagine dictating your letters and filing the tape directly on to your computer at home or in the office to be printed out. This and other developments in computer technology, such as video mail, computer-based learning and of course video conferencing are not far from reality according to Dr Steve Young in the Information Engineering group. 'There has been an accelerating trend over the last few years to use audio and video within a wide range of computer-based applications,' explains Dr Young.
Young's team is involved in a project with Olivetti Research to set up a system for retrieving video mail messages. Regular use of video mail results in large archives of video messages being amassed and this brings with it a serious problem. Users are unable to find stored messages, since unlike text, there are no simple ways to search for a key reference. By using word spotting techniques, keywords can be identified in the audio soundtrack and hence the required messages can be retrieved. This involves a considerable amount of original research, as messages have to be processed at a fraction of real time and with acceptable accuracy. The key challenges are to achieve acceptable word matching performance, to accommodate messages from unknown speakers and to allow arbitrary keywords.
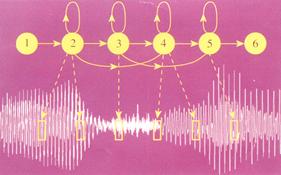
A hidden Markov model of speech.
Software toolkit
This project, which is funded by the DTI/SERC under the joint framework for information technology (JFIT), forms just part of the research being carried out by Dr Young's team. Other projects include large vocabulary recognition funded by SERC, audio document processing funded by Hewlett-Packard and a European project to establish a language independent assessment framework for large vocabulary recognition funded by the EC.
The team has already developed a software toolkit called 'HTK' which can be used to build a voice recognition system which can deal with up to 5000 words. It uses hidden Markov models, which indicate how sounds statistically change with time. Using this system a best-fit model can be used which gets over many of the problems caused by the fact that we do not pronounce the same word exactly the same way each time we use it, and, of course, different speakers can pronounce the same word very differently. The HTK-based speech processor has already proved itself comparable to the vastly more expensive American versions. It also provides an ideal environment for research and development in speech technology and as a result, it is now used at over 70 sites worldwide. Originally distributed through the University's own company Lynxvale, in Cambridge, the marketing of the system has now been taken over by Entropic Research Labs in Washington, DC.
HTK is under continuous development and currently it is being extended to handle up to 20,000 words of continuous speech from any speaker. This goal is currently the focus of an international effort and the Advance Research Project Agency in the US has defined a standard test for recognisers with this capability called the 'Wall Street Journal' task. Many of the world's leading research groups will take part in an evaluation based on this task in November of this year.
The Cambridge team will be the only UK group to take part. However, it's an enormous challenge. 'ARPA will supply us with about 50 hours of speech to train the system,' says Steve Young. 'That takes about six Gigabytes of disk space just to store it.' Given that training hidden Markov models is a computationally intensive process, finding ways to handle this amount of training data efficiently is one of the key problems that has to be solved.
| number 1, summer '93 |